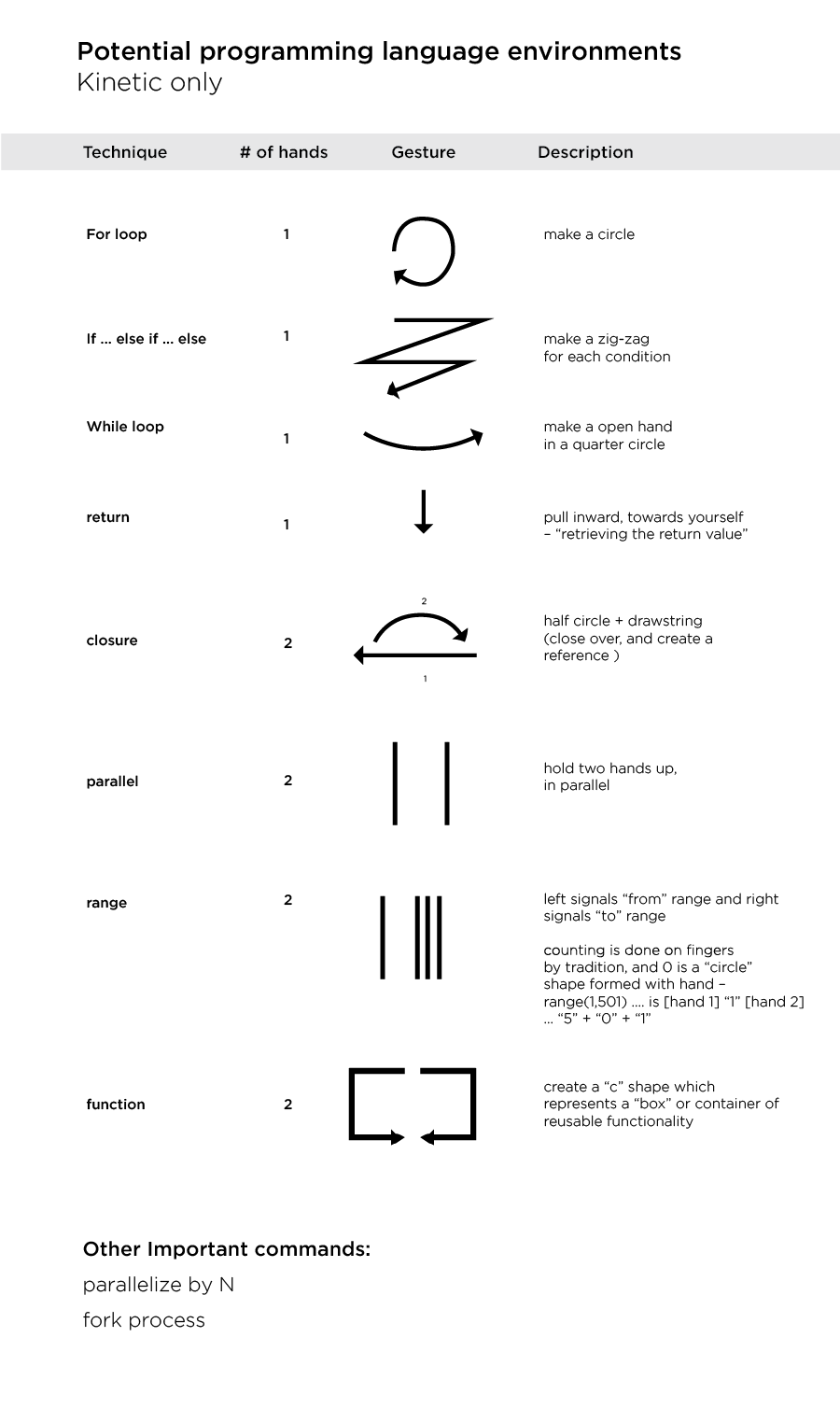
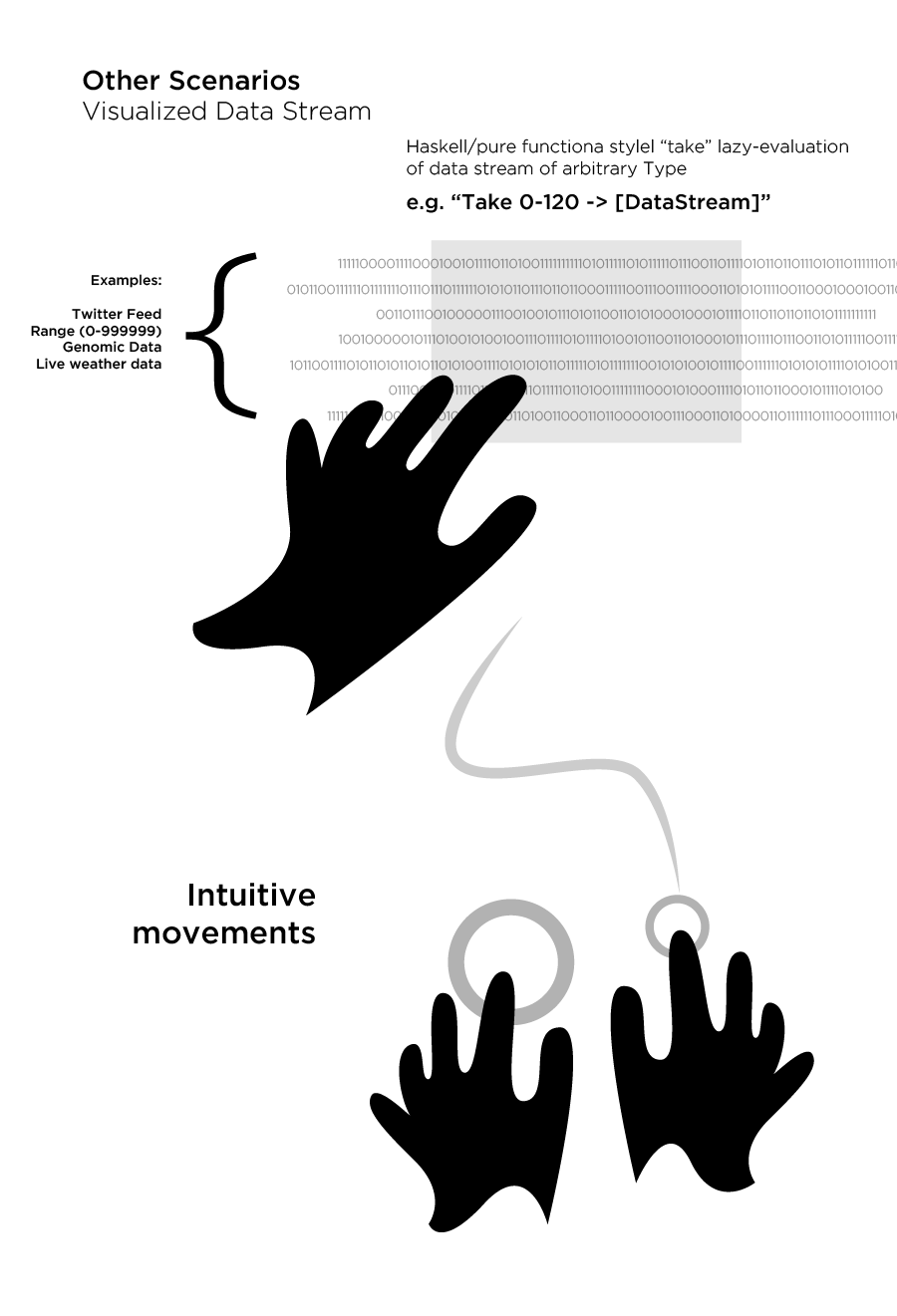
The idea is very simple and straightforward: take existing branches of science (names) and generate new combinations to see if interesting new fields may arise.
Why? I have a suspicion that many new fields are waiting to be discovered, and many fields that now exist as commonplace were once not even fathomed, and if so, likely considered silly or irrelevant. So anyway, let’s see what happened.
Inputs
First, let’s consider the inputs that I’m going to use. I did a quick search on Google for “list of scienctific fields” and got to a nice, uniform list on Wikipedia here: https://en.wikipedia.org/wiki/Index_of_branches_of_science.
I then prepped that for python, and wrote a simple program – all of which can be seen here: https://gist.github.com/christabor/264386fe5fd9e1b0412a41659b994769.
You can run it yourself, (just download the single python file, and from command line, run python path/to/downloaded/file.py) to see new results.
If you wanted to combine more than one field, you could tune the itertools.permutations argument to where r=XXX is much higher, but this will very quickly crash your computer since if the number is more than 4 (probably even 3) as it converts the results to a list which will automatically allocate all the required memory to create 6294 combinations (156531800881) - so probably don’t do that.
Anyway, enjoy! Hopefully you found it potentially insightful, or at least comical!
]]>Using env vars
First and foremost, use environment variables, ala 12factor.net. This is a hugely important way to improve portability across configuration management tools, as well as infrastructure your application will live on. Env vars are a conduit for easy passing of information across just about anything. You can even do cooler stuff, like Feature flipping.
Deploying apps with VCS
This is pretty common. You have a source repository where your code lives under version control (right!?), whether it be git, subversion, bitbucket, bazaar, mercurial, etc…, and you download the code into some directory on a node you wish to deploy with. Then you do your service setup (say launching the appropriate web server, starting a database) to get things running.
The first problem with the above
There is a one issue that consistently comes up when I did deployments this way. The first is that of authentication; when you want to pull down your code, you have to provide some kind of authentication mechanism for your source control. This is typically done with ssh for security reasons. However, if your source code is publicly available, it can be done with https.
But this requires maintaining ssh keys on the host, or hard-coding the username/password.
You have app dependencies, right?
Chances are great your app has dependencies. Let’s say, you’re developing a flask app. You will need flask, itself having a plethora of dependencies, along with any other app extensions you want. So what do you do? Typically this is approached with a requirements.txt file, which is either manually handled or generated with pip freeze > .... Unfortunately, your app is still being deployed with version control, unlike the simple method of pip, like these packages. And if for some reason you use setuptools, you have to keep requirements.txt and setup_requires=[] in sync (and don’t think about reading the file in your setuptools python script–there are pathing issues that will make this a brittle solution on many systems!)
Enter packaging
So the answer turns out to be real simple; make your app a package! This produces more than one useful effect, right out of the gate:
- Makes your app more dependable because it enforces good standards to make it work with a typical pip install (ala 12-factor app).
- Makes your dependencies automatically install before your app is installed (when using
setuptoolssetup_requires=[]keyword argument) - Allows you to do a
pip install myappand be done.
I know this has its fallacies…
If say, you have a self-hosted pypi, with the above approach you would still have to authenticate to it. And there are potential configuring you have to do here (e.g. pip.conf, .pypirc files). But the ease of having pip be your one handler for all packages and dependencies negates a lot of this, in my opinion, and is only applicable to some of these certain cases.
And when it comes to a simple install, if the package is public there is no authentication to worry about.
]]>In case you aren’t familiar, the idea behind it is simple enough: you bake features, complete or otherwise, into your code that moves through the CI cycle, right into production. Yes, you heard that right - you write incomplete or undecided software and put it in production!
At the risk of abusing the term, I think that is actually an important aspect worth noting. While the idea of the software in question being incomplete is far from a valid core definition, it does highlight some of the perceptions that go along with this strategy.
These perceptions include: push often and fast, have a CI pipeline to automate the testing, automate validation and promotion of code across development tiers (a dev, staging and of course prod server, along with any replication or other high availability concerns). I would even throw in A/B(X/Y/Z) testing in here as well, because this is often an important strategy in large scale applications that have a quick product development lifecycle.
So, assuming you agree with the above, let’s get past the actual definition and into the core thesis of this article, namely implementation.
I apologize in advance for the long-winded pretext as I’m now going to introduce three words that effectively sum up my proposition:
Use. Environment. Variables.
But wait, there’s more!
Environment variables are fantastic for modern development. I’ve switched to using them for just about any data related to configuration management in my day-to-day development workflow.
This has been heavily influenced by the www.12factor.net manifesto, and one of the core tenets is to store configuration in env-vars.
I have used this model successfully to write cross-functional configuration for a completely disparate set of tools that were out of my control (at work): Pivotal Cloud Foundry, a Pivotal Labs Platform-as-a-Service (ala Heroku, et al), Puppet, a ruby based DSL and distributed service for config management, and of course plain ol' local development. All without changing much, if anything. All env-vars.
Now, back to feature-flipping.
I’ve seen this done one way in the past, and it worked pretty well. When I worked at https://www.zulily.com features were toggled on in php if blocks, using a series of helper functions. This of course made for quite ugly code, but it worked. Behind the scenes this was actually persisted in a Redis key/value store, and an administration panel was created for flipping them off/on in real time.
However, this creates quite a lot of infrastructure headaches, and it does not work at a tier level, unless you persist based on differing keys (namespaced keys, with a prefix of some sort), or you add more Redis instances for different tiers, and target them differently depending on the hostname. Quite a lot of ballooning infrastructure cost and maintenance, if you ask me.
So, this is just one example that I have from personal experience. There are probably many other ways to do this. Local files, other data stores, network requests to some kind of feature “registry”, etc… ultimately though, these are all the same, in that they defer to a protocol and service.
But what if instead, we just used env vars? Let’s just work it out. All code below will be in Python unless otherwise noted.
import os
FEATURE_A_ENABLED = bool(os.getenv('FEATURE_A_ENABLED', False))
if FEATURE_A_ENABLED:
do_something()
Then, with our config management, we can simply inject the variable automatically:
SERVICE_LEVEL = os.getenv('SERVICE_LEVEL', 'DEV')
if SERVICE_LEVEL in ['STAGE', 'PROD']:
os.environment['FEATURE_A_ENABLED'] = False
else:
os.environment['FEATURE_A_ENABLED'] = True
Granted, the above example is contrived, you can imagine your config management software of choice handling this.
This would give us feature_a in dev only, but not in stage or prod. Conceptually, you can make it more granular if you like, say, to certain hostnames, or certain regions, etc… but really the power is in your hands.
Hopefully this helps in your development and release workflow!
]]>- personal sanity
- enjoyment of the craft
- simplicity
- maintainability
To that end, I often find a few traits are necessary for code to work really well and be pleasant to work with/extend/understand.
A lot of these concepts have mathematical backgrounds, but I am intentionally ignoring the minutae in favor of practical expressions of these formalisms.
- small, modular ‘units’
- stateless or state-light
- simple, common structure
- type aware, or type cognizant
Examples of the above in various contexts
Small modular units
Simple reusable functions, preferably organized as modules (not classes)
Simple reusable templates, preferably composed of partials (I am particularly fond of jinja2 macros in this instance)
Stateless or state-light
Functions that rely sparsely on state; instead, they use composition of multiple functions to achieve the same result.
State is maintained within the “smallest bounds” possible. A sort of “bounded context” that tries to encapsulate state in the smallest function required, so it does not float around, polluting namespaces, or causing collisions at different scope levels.
Simple, common structure
Structure in this context is more about the “shape” of the data. What I mean here is that code should try to follow some basic rules of thumb:
Rely on simple data structures (for configuration, for arguments)
- Have a reasonable arity (number of function arguments) to allow for composition, higher order function generation (currying, partial application, functions that return functions that are customized)
- Uses data structures in place of objects
Note that code and data are often used as separate entities, but in reality there is a large crossover between them. For example, there are a few scenarios where data makes more sense than using “code”, where code is meant to mean to be some executed function, class, or conditional logic:
def get_foo(key, *args, **kwargs):
mydata = dict(
key1=somefunc1,
key2=somefunc2,
)
try:
return mydata[key](*args, **kwargs)
except KeyError:*
return None
is preferable to:
def get_foo(key, *args, **kwargs):
if key == 'key1':
return somefunc1(*args, **kwargs)
elif key == 'key2':
return somefunc1(*args, **kwargs)
return None
Reading data structures is much easier than navigating conditional logic, and is also more maintainable.
Type aware, or type cognizant
Another important principle here is using the simplest types possible. This is a common UNIX adage, and is part-and-parcel to its philosophy. The designers of the pipe model that is the crux of command line programming through bash and other shell interpreters even ensured that data returned in the simplest format (strings, delimited or otherwise) so that they could easily be piped and moved throughout different functions simply.
In the scope of modern programming, this may be slightly different, but the rules are essentially unchanged – simple types for functions, classes, etc… to ensure interoperability.
Consider the following
def hello(obj):
return 'Hello {}'.format(obj.name)
versus:
def hello(name):
return 'Hello {}'.format(name)
The latter reduces the argument in terms of complexity: an object property becomes a string.
It is not hard to argue that a string argument is significantly more interoperable than an object property.
Conclusion
I hope some of these basics seem reasonable, and if so, you’ll consider adopting them in your practices. I can’t take credit for any of these rules; they’ve been there for decades. I can espouse the virtues of them though!
]]>This post is about a particular aspect of that book, outlined briefly towards the end, what I’ve called “ecological clustering”. The background is this: businesses tend to produce waste and consume resources, materials, etc…, but are operating in isolation. This creates immense waste and environmental destruction, because no business operates as a system, when in fact it should.
The idea behind one solution, outlined int he book, is simple: businesses form symbiotic relationships with each other, forming ‘communities’ based on their resources – from their inputs (materials) to their outputs (waste). This idea hinges on cooperation, and it’s a very forward thinking methodology. Essentially, companies cooperate and agree to exchange materials, where one material may be trash for one company, and treasure for another.
My idea here has been to turn this into a programmatic problem, and create an algorithm that will find all useful relationships and map them such that you can derive a list where waste OUTPUTS for one company are mapped to material INPUTS for another. This gives you a picture of companies that should be working together.
Examples
Let’s make a few toy examples, that may actually have some real parallels.
“Starbocks”
- Inputs: “Coffee (Beans)”, “Water”, “Milk”
- Outputs: “Coffee grounds”, “Wastewater”, “Cardboard”, “Food scraps”
“Composting Northwest”
- Inputs: “Coffee grounds”, “Food scraps”
- Outputs: “Soil”, “Fertilizer”, “Earthworms”
“Sustainable Farms”
- Inputs: “Earthworms”, “Chicken feed”, “Cardboard”, “Water”, “Fertilizer”
- Outputs: “Chicken meat”, “Chicken eggs”, “Wastewater”, “Food scraps”
“Wastewater treatment Northwest (WTNW)”
- Inputs: “Wastewater”
- Outputs: “Water”
Now, the algorithm is pretty straightforward. The most important aspect is that we’ll be using an inverted index to create our mapping, which allows single keys (in our case inputs and outputs) to map to all their locations (their occurrences, here).
for all companies,
make an inverted index of the input and the company associated with it
make an inverted index of the output and the company associated with it
Then, make a list of pairs of companies where one companies output is another companies output, and vice versa.
Encoding our data
The next important step is to encode the data properly, so we can actually use it in a program. Converting our previous examples into a proper, Pythonic format, we get:
relationships = {
'in': {
'coffee': ['starbocks'],
'coffee-grounds': ['composting northwest'],
'water': ['sustainable farms', 'starbocks'],
'wastewater': ['WTNW'],
'cardboard': ['sustainable farms'],
'milk': ['starbocks'],
'chicken-meat': [],
'chicken-eggs': [],
'earthworms': ['sustainable farms'],
'fertilizer': ['sustainable farms'],
'soil': [],
'food scraps': [],
},
'out': {
'coffee': [],
'coffee-grounds': ['starbocks'],
'water': ['WTNW'],
'wastewater': ['starbocks', 'sustainable farms'],
'cardboard': ['starbocks'],
'milk': [],
'chicken-meat': ['sustainable farms'],
'chicken-eggs': ['sustainable farms'],
'earthworms': ['composting northwest'],
'fertilizer': ['composting northwest'],
'soil': ['composting northwest'],
'food scraps': ['starbocks', 'sustainable farms'],
},
}
The algorithm
def generate_relationships(d):
matches = []
pairs = []
for _input, companies in d['in'].iteritems():
for _output, companies2 in d['out'].iteritems():
if _input == _output:
matches.append((companies, companies2, _input, _output))
for c1, c2, inputs, outputs in matches:
if not all([c1, c2]):
continue
if c1 != c2:
pairs.append((c1, c2, inputs, outputs))
print('{c2} <=outputs=> "{output}" so it should pair with {c1} '
'which =>inputs<= "{input}"'.format(
c1=c1, output=outputs, c2=c2, input=inputs))
return matches
if __name__ == '__main__':
generate_relationships(relationships)
The above function takes a dictionary (key-value pair) as input, finds the input relationships, and maps them with output relationships, for all companies in each input list.
So, here’s an example of the output when run against our previous data set:
['WTNW'] <=outputs=> "water" so it should pair with ['sustainable farms', 'starbocks'] which =>inputs<= "water"
['composting northwest'] <=outputs=> "fertilizer" so it should pair with ['sustainable farms'] which =>inputs<= "fertilizer"
['starbocks'] <=outputs=> "cardboard" so it should pair with ['sustainable farms'] which =>inputs<= "cardboard"
['composting northwest'] <=outputs=> "earthworms" so it should pair with ['sustainable farms'] which =>inputs<= "earthworms"
['starbocks'] <=outputs=> "coffee-grounds" so it should pair with ['composting northwest'] which =>inputs<= "coffee-grounds"
['starbocks', 'sustainable farms'] <=outputs=> "wastewater" so it should pair with ['WTNW'] which =>inputs<= "wastewater"
Very useful! This could of course be manually done, but the point is to automate it en masse, and find unexpected relationships across a swathe of industries.
Parallelizable work
This is an example of an algorithm that would be considered “embarrassingly parallel”, because the format of the algorithm, and the fact it operates on structured data sets, means it can be partitioned up into sections and then split across any number of machines to be done in parallel.
For example, you could take this algorithm and plug it into the MapReduce paradigm, where you could then map the work across a cluster of computers, and then reduce the results to the input/output relationships.
This would make finding insights amazingly easy, and could help find novel solutions to sustainability!
]]>Using highly terse symbols, a web-development language is expressed through a few characters corresponding to common web development design patterns, as an experiment in language design.
A pure algebraic, simple version
- W (Web application) = (R, C, T, M)
- R = Routes [R0, R1, R2, Rn-1]
- C = Controller (view) [C0, C1, C2, Cn-1]
- T = Template [T0, T1, T2, Tn-1]
M = Model [M0, M1, M2, Mn-1]
P = partials [P0, P1, …]
- L = layout [L0, L1, L2]
- T = (P, L)
Detailed layout composition via partials – “widgetized” layouts
All pages are composed of components, sub-components, etc… but this is a formalization of that common observation.
layout (composed sections) section (composed collections/static/model) collection loop format display (grid, carousel, etc.., – widget) collection loop (iterated view block) model (single view bloc) static block
Structure/required types
MODEL
* Collection
* Create collection
* Read collection
* Compose with collection
* Single
* Create
* Read
* Update
* Delete
* View all enumerable properties
* Filter props
* Sort by prop
* Compose with other singles
VIEW
* Display models as modular blocks
* Table
* Div-based "grid"
* UL, OL, DL
* Display plain text blocks
* Display links to other pages
* Display forms for CRUD'ing an entity
* All properties
* Filtered properties
CONTROLLER
* Get model data
* Transform (optionally):
* Property
* Composition with other
Notes: common “patterns”
These types of things can be modeled using the application algebra, but for now are simply common patterns in web app development. In most all applications, the majority of content/functionality consists of:
- static content
- entity
- actions on an entity, via html elements (CRUD actions).
- displaying an entity, via html elements.
Another algebra design example:
- Let K = Entity([…])
- E = props(K) <- get properties of model
- F = filter(E, props) <- filter unwanted props
- H = Tab(F) <- generate html table with enumerative filtered properties F
- P = {H0, H1, …, Hn} <- page = set of html blocks
- [+] = create model button
- [x] = delete model button
- [MC] = model collection
- [MS] = model single
Abstract form operations
=F= Form- =F[C - entity:name] = Form, CREATE operation on entity:name
- =F[R - entity:name] = Form, READ (display results) on entity:name
- =F[U - {fields: [field_1, field_n]} -> entity:name] = Form, UPDATE {fields} on entity:name
=F[D - entity:name]= Form, DELETE on entity:name=F[Q - entity:name]= Form, UNI[Q]UE operation on entity:name
Abstract html elements
<a>= link (url)|T|= table:L= list~c~= plain (static) content<0, N>= index enumeration from 0 to N<k,v ... [MC]>= entity enumeration, where entity is a key, value, that can be nested.
Application algebra examples (WIP)
- [MC] list on page
- [MS] details on page.
- [MC] -> list on page, with [x]
- [MC] -> list on page, with [+], and F(MS)
The idea behind this diagram is to represent three dimensions: the cyclical nature of a given subject, the temporal quality of that subjects' cycles, and the evolutionary nature (or growth/decay if you will) of that subject over time. In some cases there might be a fourth dimension represent, but we’ll focus on these three.
Dialing it back
Now, it’s fairly common to see a diagram that demonstrates a cycle of some type. It can be purely logical, like a business process, or it can be something real and tangible, like the seasons of a year. Both of these represent some kind of cycle, but the number of discrete states/phases in that cycle can vary.
For example, a business might have twenty different “phases” of change for a given process, say how to complete some contractual obligation - but a year on Earth represents a fixed set of four seasons: spring, summer, fall, and winter.
Both of these examples represent the more common aspects: temporality (time) and cycle. And visually, they are represented as an actual cycle, typical with lines dividing up segments, and an “arrow of time” indicating the progress/change.
Adding in a new dimension
Now, what makes this diagram more interesting, and unique, is that as we add a new dimension, a new type of thinking and abstraction take place. The third dimension is a tapering of the spiral, upward. This produces the “helical” aspect, giving it a new way to represent changes in magnitude, and adding a new dimension of time, to complement the circular (cyclical) representation.
Before we could only represent a fixed cycle “length”, but now that can change, which represents the potential for a cycle’s behavior to change.
To be clear, the new diagram represents a discrete time step as each turn around a circle, and within that circle are N steps, part of the overall cycle. Moving up, along the circle in a helical fashion represents the change of another, greater time-step M.
So for example, a turn around the circle might represent 1 year, the height of the “helix” might represent 20 years. Then, the tapering or otherwise changing circumference of each year represents represents changes throughout the year, that might indicate volatility.
Recap: required data
The following data is required for the diagram:
- The name/number of cycles for a given “unit” of time to pass (for example, the )
- The discrete unit of time (e.g 1 second, 1 year, 1 century)
- The dimension that rises and falls along each cycle and unit of time (e.g. stock market volatility, total population, weather temperature, popularity rating, etc…)
A good UI structure:
- Contains modular elements that can be composed into a page layout.
- Has clear boundaries so things can be unhooked (so called pluggable)
A good UI module:
- Never assumes information about its surroundings
- Like a black box: if given the right data, will work just fine.
- Is encapsulated as much as possible with its own state and interactivity
- Is usage agnostic, meaning it can be removed and placed elsewhere without breaking, even if it requires external resources or API endpoints to function (e.g. forms, JS functions)
- Has corresponding JS and CSS that follow the same principles
- Is semantic (meaningful naming conventions)
- Is DRY (Don’t Repeat Yourself)
First off, follow the UNIX philosophy - do one thing, really well.
But how?
Take a very generalized, preferably generic concept (something very wide, not deeply domain specific - e.g. string formatting, pluralization, currency conversion), and explore the topic in as great deal as possible, providing neat, simple, modular, composeable utility functions, with easy to understand, consistent API, and unit tests.
For example, these are timeless libraries for most languages:
- string formatting/filtering
- math functions
- word translation
- string modification
- pluralization
- color code translation/generation
- munging/text processing
- low-level abstractions (machine, etc)
Try it out! Find a topic that interests you, apply your knowledge in detail, or do lots of research, and then solve the problem(s) with small, bite-sized functions that can be put together to create more complex modules.
]]>
From Wikipedia:
In computer science, a Cartesian tree is a binary tree derived from a sequence of numbers; it can be uniquely defined from the properties that it is heap-ordered and that a symmetric (in-order) traversal of the tree returns the original sequence.
[they’ve] also been used in the definition of the treap and randomized binary search tree data structures for binary search problems."
It’s an interesting, possibly obscure tree, but I found it fun to work on, especially as a way to create them more intuitively. I wrote an implementation of said tree in Python over at my personal project “Mother of All Learning” (MoAL), but as with most challenging things, I had to do a lot of back and forth on pen-and-paper to “grok” it. In the process of translating this concept into a tangible data structure that could actually be put to code, I found what I thought was a novel way to create the trees very simply, just by drawing.
Without further ado:
First, let’s look at an example: [9, 3, 7, 1, 8, 12, 10, 20, 15, 18, 5]
I find it’s easy to think of the list as being broken down into sub-lists, where each sub-list has a left, pivot, and right side.
With this in mind, we can find the pivot, which is always going to the smallest number, and then divide the list up into a sublist, where the first index is the current node, the second is the left child, and the third is the right. If left and right are empty, then the singleton list denotes a leaf.
Now, to visualize it, we use the above procedure, but for each pivot, draw a line up/down to the previous pivot, and then draw lines from the current pivot to the left and right children. At the end, you’ll get an actual tree drawing!
So, back to our example.
``9 3 7 1 8 12 10 20 15 18 5```
The first thing we need to do is find the pivot. As mentioned above, it’s always the smallest number. In this case, 1 is the pivot, so it becomes the root node, since all other elements will become leaves, and this is the first node.
1
/ \
9 3 7 8 12 10 20 15 18 5
Ok, we’re getting somewhere. Now, for each new side, we need to do the same thing. So, on the left hand, 3 is the smallest, and on the right, 5 is the smallest.
1
/ \
3 5
/ \ /
9 7 8 12 10 20 15 18
Visually, this is a bit odd because of spacing, but we can see all the numbers on the right branch (5) are to the left of 5 – it will look better once we finish it.
Next up is left, where there is nothing to be done, since each child of 3 is a leaf, and right, where 8 is smallest.
1
/ \
3 5
/ \ /
9 7 8
\
12 10 20 15 18
And again, 10 is now the smallest.
1
/ \
3 5
/ \ /
9 7 8
\
10
/ \
12 20 15 18
And now, almost done, the right side is left; 15 is the smallest here.
1
/ \
3 5
/ \ /
9 7 8
\
10
/ \
12 15
/ \
20 18
And we’re done!
I find this is a fun way to solve the problem, although this isn’t easily (or efficiently) translated into code. For that, I follow the same procedure, but use nested lists, which can then be traversed the usual means, either a while loop, or recursively. Check out the implementation if you want to see more!
]]>Typically, refactoring examples and tips and tricks online focus on very small, manageable codebases or modules. I have yet to see any article that really brings a genuine real life “worst-case” scenario to the table, and illustrates how to increase the quality and predictability of said code. My goal here is not to prescribe a very strict, concrete set of ideals, but rather to offer some examples and “rules-of-thumb” that I’ve found handy in settings that are anything but ideal.
Getting your mind right
The first thing that has to happen is a shift in mindset (assuming your mind is not already set this way!) Naturally, we approach a given problem with our experience in how that problem should be solved. In refactoring a project, this can cloud our judgment and give us a false sense of competence as we jump into it. In software, this can make things worse, quickly. And the more complicated the codebase, the more likely failures and regressions will occur.
Starting small
The biggest, biggest rule-of-thumb I have found refuge in is the notion of “small changes”. There is no limit to how small they can be, but I tend to think of it as inversely proportional to the scale and severity of the problem: the more complicated, poorly architect-ed, hard to reason about the codebase is, the smaller your changes need to be.
The reasoning is that small changes are very incremental, and these can be used to create a stronger codebase, which can then be improved upon in broader strokes; it has to be incremental, otherwise you risk regression or premature optimization, or worse, total incompleteness.
So, starting small for example, might consist of:
- making variable names more obvious
- removing duplicate variables
- isolating code into functions (basically wrap what exists into a function, and grab the data that way.)
- adding comments!
- adding docstrings
- adding documentation
- caching data when possible
These don’t alter the overall structure, but allow for consistent improvement. Another nice thing here is that you don’t spend a lot of bullshit time on the process of “what, where, and how” – you’re not classifying the refactoring, you’re just doing it.
A stepping stone to broader strokes
When you’ve completed some of the above examples, you start to feel the codebase as being a bit nicer, and in some cases, there might even be tangible improvements, say, performance or productivity. At this point, you can start in on the broader, more architectural issues, but still keep in mind you aren’t re-architecting the entire application or codebase – just breaking things apart a little bit more.
Some more examples here:
- reusing functions
- introducing namespaces (either global, or more likely, sub-namespaces)
- pulling data/configuration out of implementation code, and storing it in the right files (to introduce separation of concerns).
- either pulling methods out of classes, or adding them in – depending on the system. Often times, methods are too generic, and should be pulled off of object classes, in favor of purpose driven modules (think G.R.A.S.P.). But other times, they are thrown about disparately, and could benefit from the conceptual “tidying” that object oriented programming provides. This aspect, by its nature, has to be approached on a case-by-case basis. Often times OOP is abused and irrelevant, but other times it can greatly improve the system structure and adaptability.
Getting to a point of testability
There’s no hard science as to when you should introduce test cases and more formal verification to your codebase, but if you haven’t already got it, I would wait until you knock out the basics described in the first section. The reason being, you’ll often find yourself duplicating efforts when developing test cases and formal verification, only to quickly change it, once your refactor provides a clearer look into the structure.
Once you’re here though, the least you can do is stub out your test cases. This means coming up with test matrices for each function, or class and accompanying methods, and the various permutations of arguments that each might have, and this falls squarely in unit-testing world. I would certainly hesitate to provide integration tests at this phase, because you’re probably going to break them all once your refactor is complete.
Beginning to structure the big picture
Now you can rethink the system in the most broad (or nearly so) terms. From moving code into components and system modules, to defining clearer interfaces between classes, to investing in microservice architectures, you can start to break the code into something that might resemble a bonafide diagram. This is when you want to develop your broader testing and verification analysis, because you’re finally at a point where it makes sense to test things as-is.
Unit tests should be actively defined, if not already, and integration testing can begin as well.
I’ve found this kind of approach immensely helpful in real world cases, and hopefully, you can too!
]]>Now, what does this have to do with exploratory programming? Well, while working on this project, I find myself looking for interesting analogues or specific uses to apply each concept to. Sometimes the ideas will be simple, such as a “print queue” to understand the notion of a queue data structure, or an e-commerce system to understand many object-oriented design patterns, but even then, I’m not all that creative. So here’s one idea I’ve come up with: books and programming.
It’s really simple; you find a science fiction book you want to read (or really any fiction, but SF tends to be the easiest to find an analogue to), and then pick a topic to study. Then you marry the two topics, using one to support the other, from a learning perspective.
Perhaps an example will help clear it up: Dune + Operating Systems + Hivemind
Huh? Okay, let me explain…
Operating systems:
For me, I am studying a few different topics right now, but one of them might be operating systems, specifically the access controls between various components. For example, operating systems pretty much all have the notion of a “protection ring”, which specifies boundaries for what a user can do, and what the user cannot do. From my sparse knowledge, this is typically exemplified in a UNIX system as a kernel/application relationship, where the kernel acts as an intermediary between the hardware and applications, applications being what the user has access to.
Dune
As for the book portion, I’m currently reading a Dune book called “The Machine Crusade”. It chronicles the battle between the “Thinking Machines” and humankind. The part specific to this are the various robot forces; the overmind “Omnius”, the supreme leaders, called Cymeks (specifically one named Agammenmon), and the robot leader named Erasmus.
What struck a chord with me was the notion of having different layers of mental capacity and thinking. It appears the machines have an overall supreme intelligence (Omnius), and then their own levels of personal intellect. This is essentially another word for the idea of a hivemind, or collective intelligence, specifically one that can be shared. If you’re familiar with the Halo book series, the group known as the “Forerunners” have something like this, called the “Mantle”. It is not-so-uncommon trope in many Sci-Fi books and movies.
Putting it together
Okay, imaging those two things in conjunction, an idea popped into my head. “What if you could use the notions of networking/distributed computing, and operating system principles to design a very primitive architecture that could represent global and singular machine intelligence?” While this may not be a typical thought for most people, this concept popped into my head.
So, there you have it – books and programming, the two intertwined. This post isn’t really a post about a specific implementation – I would instead have you indulge many of your brain sections in this activity: your creative, your imaginative, your critical – have fun, and go nuts!
]]>The idea of “always working” is fundamentally flawed.
There is a pervasive notion in most all “modern” cultures that the default state of all people in a society is to work, and then have free time after the work is complete. If you aren’t working, you’re either:
- A child, in which case you “should be in school”, which is just another form of work, or work training, at least.
- A bum, leeching off of society.
- Disabled, which by some (not I) are regarded as leeching off of society as well.
- Retired - the one “respected” non-laborer of the group, whom is often given respect, probably because of some notion of “having earned their right to retire”.
Let me try to convince you that this whole thing is fundamentally flawed.
Not Flawed for certain societies
I should point out, that it’s not flawed in all cases. In a society that adores inefficiency, one would expect a certain consistency in labor.
In a society where the populace is not united, there is going to be some chaos and lack of cohesion in goals, which manifests itself as incongruent philosophies and a general lack of “progression”.
Flawed for progressive societies
Having demonstrated a hypothetical (and arguably straw-man) example, let me just step back and look at a society where I consider this notion of “forever working” to be incongruent with, and flawed, for.
Here, I define a progressive society as one that “works” for its people to better their lives. What does this really mean? To me, it means the society:
- Induces a safe environment, both mentally and physically
- Induces a more peaceful attitude on the populace
- Promotes self-actualization (pursuance of passion, freedom to experiment with interests, etc..)
- Promotes higher intelligence, and critical thinking
- Promotes co-operation
- Promotes diversity and acceptance
- Does not tolerate coercive or combative attitudes
- Seeks to harmonize with natural ecosystems and find a balance that promotes biodiversity and sustainability.
- Recognizes differences and strengths/weaknesses but promotes equality.
Achieving all of these things in a society might be the key to a “utopia” or “golden age”; but I suppose it depends on who you ask.
Given these criteria, let’s systematically show how a society that does not provide a living wage might be incongruent with each ideal.
1. Induces a safe environment, both mentally and physically
This one is mostly innocuous here, but I might argue that having to work in a job you hate would promote both physical and mental stress. I’m not going to delve too far here as this borders on common sense, but I’m sure most people can relate either directly, or by proxy.
2. Induces a more peaceful attitude on the populace
See 1. This definitely cannot promote a peaceful attitude, since people are forced to work in conditions they do not like. You can use alternative methods, like yoga, meditation, focused breathing or exercise to help offset the effects, but ultimately you are fighting an uphill battle.
3. Promotes self-actualization (pursuance of passion, freedom to experiment with interests, etc..)
This one is perhaps the most obviously incongruent. A living wage promotes self actualization by design, because each individual is free to choose their own direction (so long as it does not conflict with the laws and morals of the society.) Lack of a living wage actively prevents someone from self-actualization. In capitalist societies, this gets worse: a capitalist society promotes an attitude of one-upmanship, meaning industry leaders must constantly fight to be better than their competition, simply to survive.
And even if a company happens to find itself a titan with no rivals, it has no reason to innovate, and simply stagnates, while still (contradictorily) trying to “grow”, for growths sake. After all, if a company has no reason to grow, it has no reason to continue employing many of its employees, and so reasonably would fire them. It has some striking parallels to a cell that just won’t die, growing and growing while stealing resources from the body (this is called cancer, by the way). I’ll refrain further from this tangent as it deserves a book in its own right.
4. Promotes higher intelligence, and critical thinking
This one is kind of a wash; a capitalist society may very well promote higher intelligence, and critical thinking, simply because it can be required to further ones financial situation. However, I would argue it also promotes misguided betterment. Lest one end up with a degree in the canonically unmarketable degrees of “communications” or “anthropology”, people are forced to move in the direction of the market, approximating their desires by finding a degree or job role that is only somewhat congruent to their interests. And later on, as I describe automation, this becomes worse, because fewer and fewer jobs will exist to cater to someones interests.
5. Promotes co-operation
As pointed out in 3 and 4, this flies in the face of capitalist society. At the corporate level, co-operation is only used insomuch as it benefits a company. It would be better labeled as “strategy” than co-operation (and often it is, alongside a handful of misused military idioms espoused by corporate leaders, such as “working in the trenches”).
6. Promotes diversity and acceptance
If not for the advocacy groups that exist in first-world countries, this would not exist except for the morals of the individual. But these groups do exist, and so we’ll accept this.
7. Does not tolerate coercive or combative attitudes
This is not terribly relevant to the point of this article, so I’ll just skip it.
8. Seeks to harmonize with natural ecosystems and find a balance that promotes biodiversity and sustainability.
As evidenced by countless eco-disasters, capitalism is and has been at odds with biodiversity and sustainability, unless the acceptance of it has direct strategic consequences to the bottom line of the corporation. What I mean here is that, while Shell, Exxon, BP or some other energy company may invest in solar panels, sustainable practices, or clever marketing departments, they do so only out of necessity, not out of some moral high-ground (no matter what glorious speeches a CEO gives, or green-washed commercials a marketing team may produce.) The moment a sustainability practice becomes cost-prohibitive (and is not mandated by law), you can bet your ass the company will drop it in favor of something more profitable. When the charter for a company is to increase dividends above all else (as it is for a corporation), you can’t be surprised that it behaves accordingly.
9. Recognizes differences and strengths/weaknesses but promotes equality.
See 6.
Enter automation
Let’s step back for a second, to talk automation. Automation is really a crucial part of my argument, as it is the key force that will increase the bottom line of companies moving forward. All corporations will at some point seek to automate. There are two primary forms of automation:
Automation of business processes, where a typical group of people communicating and delegating becomes a complex task that is automated via software (and accompanying hardware), divided into business rules that can automatically trigger events and react, like a person.
Automation of repetitive tasks, where either a physical task (like spot welding parts to a car) or mental task (calculating mortgage adjustments or loan risk) are replaced by machines.
These both cover the two major job types: physical laborers or knowledge workers. Either job is at risk, and many jobs in each category are at risk. Not only that, while it has been argued that new jobs are being created to replace these, the automation is happening at a faster pace than job creation.
Enter Oscar Wilde
In “The Soul of Man Under Socialism”, a personal favorite quote of mine can be found:
At present, machinery competes against man. Under proper conditions machinery will serve man. There is no doubt at all that this is the future of machinery.
To me, his point is that machines are being driven by rulers seeking to drive the bottom line, by using machinery to remove the necessity of people (except the people in charge of the machines!)
Automation in jobs is not speculation or hypothesis; this is actively happening in all job sectors, and will continue to happen. The crux of this article really is “what is the logical conclusion of complete job automation”?
A system of self destruction
I argue that this system is bound for self-destruction, because it will collapse on itself. How so? Because as companies automate jobs, more jobs are lost across more industries, and since there is no living wage, people have less money to buy products, therefore there is inevitably a “tipping point” where the corporation reaps profits until there’s no-one left to buy, because all the jobs have been automated, and no-one has any money!
It has been said that a company should “find cheap workers and expensive customers”, because there’s no money to be made in investing in employees, while there is a treasure trove to be made from customers.
The irony here is that customers have jobs elsewhere, so at some point, if a competitor employs many of your customers, and decides to automate all of its jobs, then all those employees are no longer your customers!
This principle is associative, so lets explore how this would pan out.
Let’s say Company A has 1,000 employees, who happen to be customers for Company B. Let’s also say Company B has 1,000 employees, who just so happen to be customers for Company A!
Right. So now let’s say, Company A will have found a way to automate all its jobs. Company A promptly fires all its employees. This means, Company B has lost all of its customers. Company B is not doing so hot, so Company B goes under. Well now, Company A has lost ITS customers! Naturally, no one exists to buy their product, so Company A has to fold as well, even after they did so well with all that automation!
Real life is much more complex, but there are inevitably customers that are also employees in all businesses. This too, borders on common sense. The point here is that all companies, whether they are direct competitors or not, are intertwined in a complex relationship of customers, employees and competitors.
Propping up this tragic comedy
Ironically, automation leads to the inevitable dissolution of a corporation, albeit the timeline may be much longer, and short term gains are very desirable. The only way out of this mess, I think, are two options:
A living wage
A living wage acts as a buffer for the transition to a more advanced society. It is a permanent stimulus package to help prop up the businesses, as less and less people have money to put back into the system when automation takes their jobs.
Ultimately, this should be replaced by a more progressive society (using the principles I’ve described above).
Conclusion
Only time will tell, as to whether we need it fast, or if we can slowly iterate to a better governmental/societal model, but for now, it is a necessary stop-gap.
I hope you can agree a living wage is the most humane and logical thing we can do for our labor economy.
]]>I am starting to wonder if all of mathematics are simply ways to express “computation” on number systems or patterns of numbers – e.g. calculus, arithmetic, etc, all being different “ways” (perhaps crude, perhaps elegant, I’m not sure yet) to perform transformations on a structural system, that system being composed entirely of numbers. It’s as if numbers themselves are some encoding device for a meta-structure that exists in the fabric of reality. This is partially true, as the symbol you use doesn’t much matter, a 1 can be replaced by an “!”, 2 by “@”, etc…, so long as the operations remain intact. This is plainly obvious by looking at the unary number system, which is still intuitive to us (I, II, III, IV, V, etc…)
See for example: I + II = III, I + IV = V, (IV + I) * II = X
…seems odd at first blush, yet it makes sense upon closer inspection – so then symbols aren’t all that meaningful, until we specifically project meaning on to them! This is certainly true with math: all algebraic symbols are meant to be mostly meaningless - as simple “stand-ins” for a concept, that don’t “get in the way”, and allow you to do the actual operations without the metadata of the symbol itself – which would be a distracting piece of information.
All of this is pretty hand-wavy, and feels a little like pseudo quantum mechanic type babble, but I think it’s an idea worth exploring, and it’s still more concrete than most jargony new-age talk. It’s likely this has been explored before, and even has mathematical models to explain it. I’d like to know more!
What really blows my mind though, is that we are creating new maths, that involve algebraic structures, much of which don’t rely entirely or much at all, on numbers, at least at first blush. They simply encode some abstract understanding, using basic symbols. I am thinking in particular of category theory. It is meant to bridge disparate maths together, and help understand a structural pattern to any math system. It calls into question what symbols are, what thought is, and even what numbers are. It all seems to be basic symbolic representation, but its become so abstract, it starts to bend back on itself, in that it becomes so hard to understand, because it’s like peeking into the brain while trying to use that very same brain to understand itself.Every system seems to be encoding some kind of “reflective identity” property that is triggered under certain “introspective” circumstances, and acts as a sort of blockade. This is kind of an analogue to the notion of reflection in computing, where objects can inspect and understand themselves (of course by a program written by a user, not the actual code itself, somehow becoming “magically aware”). Another tangent to this is the notion of a quine), which is a computer program that produces its own source code as output.
Anyway, enough babble mumbo jumbo - I’m glad to get that all out. I’m excited to learn more about the structural nature of numbers though, and how I can actually apply it to create something cool! I think understanding the ladder of abstraction will help make the application of these ideas easier.
]]>(if you’re a seasoned programmer and don’t need the preface, skip on down to the lower section about paradigms) If you’re really, really seasoned, you might skip even further, to the core paradigm in this article - dataflow.
As a preface, let me say this: having programmed professionally for about three years now, there is still so much for me to learn. I will probably be learning all my life and still have not have truly mastered programming.
Programming is interesting on so many levels. I often tell people it’s like climbing a cloudy mountain: you have a general idea of where the top is, but the higher you get, the further the top seems, and the more enshrouded you become. You can see high from up there, but you still can’t see the tip-top.
That isn’t to say that it gets harder; merely that its not something that can be looked upon and digested in one sitting. It’s a long and wild ride, and if respected, it can take you into a new way of understanding the world around you, one that is deep and even unsettling.
The reason for the proliferation of programming paradigms, highly specialized domain experts, and increased complexity in technology is probably hard to pin down. It could even be argued that it hasn’t become more complex, but rather refined. Either way, we’ll leave the philosophy of it for another day.
All of this is important, but not vital to understanding some of the core principles of systems and the computations they invoke.
This is not the perfect order, nor does it claim to be the typical learning path for programmers, nor does it exactly reflect my personal experience, but we’ll use it as simply an guide on our journey.
So young Padawan, let’s just say you’ve started programming: you did some tutorials, read a book, whatever. You’ve got the basics down – functions, for loops, data structures, variables, conditional statements. You’re hot shit, and you are writing scripts like no ones business.
Time passes… now you’ve been doing a bit more, and you want to raise your skill – either by necessity or curiosity.
Now you’re learning about things like state, program composition (and decomposition), organization, naming conventions, hell, even debugging and troubleshooting!
Wow, this is really powerful, really cool stuff! And you feel totally in control. That’s an important distinction here, for reasons I’ll return to later.
Look ma, two hands!
Now things are getting interesting. You’re at a stage that most professional programmers might consider “knowing enough to get into trouble”. Not long ago I was there, and it felt really exhilarating. Nothing like a good roller-coaster, but hey, different strokes for different folks.
You might have some friends who program, or maybe you’ve posted code online in a public forum of sorts. You might get some virtual high-fives, but there’s a good chance that some people are attacking your code – what gives? Suddenly the honeymoon is starting to wear off – did I make a grave mistake?
If you’re tenacious, and you either want to make a career out of it or continue as a hobbyist, you’ll keep on keeping on. If not, you might just call it quits and chalk it up to an interesting experience. Let’s assume you’re going to stick with it. What’s next? There’s a good chance you’ll learn that people are talking a lot about “computer science”. Sounds hifalutin – what kind of science is really involved?
You’ll learn about things like data structures, about using them to store information in a way that makes your code faster, more robust, and easier to reason about. You’ll even get to the classic comp-sci stuff – Big O notation, where you learn how a program will perform as you increase the size of your dataset, and can even graph it all nice and pretty like. You’ll probably learn about the classic data structures, which are all just abstractions to what a computer really is – a big ass chunk of memory and some logic gates.
These data structures are not commonly used for most domains, as they have been abstracted into libraries and tools, but it’s good to know (sometimes) and you’ll learn it anyway. There is a certain mental masturbation involved in some of this learning, but suffice it to say that it can be useful to understand how things really work “under the hood”.
The kind I’m talking about are the classics - trees, linked lists, arrays, hashes, heaps, tries, etc…
As I said, they are abstractions – at the end of the day, it might be a tree shaped data structure (tree), it might be a list of pointers that link one section of memory to another (linked list), it might be a block of contiguous memory (array) but you’re still at the whims of the machines' guts. You’re complex program might be traversing some data, writing things to disk, posting things to another application, sending messages back and forth across continents – it’s still ones and zeros, bits and bytes, electronic switches and logic gates.
Remember I said that control was an important distinction? The reason why might be clearer now. The more you program, the more you tend to realize how much is out of your control. It’s very easy to write “one-off” scripts, but taking that mindset into a large, unwieldy code-base will get you into trouble. At this point, you are at another crossroads – specialization. You have learned quite a bit, and you’re at a level that could be arguably “professional”. You’ve got some comp sci under your belt, and you’ve done some real programming.
Engineering to the rescue!
If you’re going to continue professionally, I think it’s important to take a step back and think more in terms of engineering. If you have done extensive coding, you will have undoubtedly uncovered issues, found or pondered solutions, and become more concerned with the process of your work.
Let me also say this; the fact that software engineering and computer science are two different fields cannot be understated. I find it to be a red flag if someone says otherwise. Suffice it to say, these two categories are solving different problems. Engineering is focused on structure, maintainability, dependability and understanding of real, every day systems and programs. Computer science is intimately involved in both theory and practice, at a highly granular level.
So, now you’ve been doing some engineering. You’ve learned about design patterns, which are just common ways to write a program that are generic enough to be reused, and have been battle-tested. You’ve learned about program structure, how to organize your code, why breaking things up into small, reusable pieces is a good idea, and how important abstraction is. After all, a highly specific tool is rarely a useful one – unless you’re the kind of person who loves ‘as-seen-on-tv’ products. Understanding and applying abstraction is arguably the most important aspect of what makes a programmer, a programmer.
Maybe you’ve also learned about design constraints, working in teams, making trade-offs when choosing or developing tools, working with deadlines, understanding requirements, maybe even that weird “Scrum”, “continuous integration”, or “agile” stuff people keep talking about. It’s effectively the art of getting things done.
There’s also a chance you’ve heard or used an “API”. This means application programming interface, and while it is thrown around willy-nilly, it generally refers to the way someones code (read: library, module or tool) can be used, and what’s available for the end user.
Enter the paradigm
At this point, there’s a good chance you’ve been exposed to something called a “programming paradigm”. Once again, it might seem hifalutin, and it can even feel alien until you’ve done enough programming to fully “grok” it, but you may have heard of it. If you’ve gone through computer science, it was probably talked about, and probably centered around “Object-Oriented Programming”. Sadly, this is a stain on computer science classes in my opinion, because it is often sold as the end-all-be-all as a way of writing programs.
The reality is, there are a multitude of paradigms. In the context of programming, a paradigm is simply a way of thinking and structuring your code. All programs must run through a computer that is Turing complete, so it doesn’t matter much to the machine what paradigm you’ve used, it either works or it doesn’t.
However, programming is done by humans (for now). As such, we need ways to understand it better. It’s not exactly intuitive the first time around, though some folks are trying to change that.
Thinking with objects
So, object-oriented programming (OOP) tends to fall into two camps, the difference of which are not understood well enough by most programmers, particularly those “set in their ways”. I say this because OOP was invented by the prominent Alan Kay with his creation of the SmallTalk language, and this fact seems to escape many professional programmers. The more commonly taught form of OOP is basically the form practiced by Java programmers. Generally speaking however, OOP stresses the importance of thinking of code as objects, each of which can have their own internal state, and ways to manage that state by way of setter and getter type methods. Inheritance is also a huge component, and it is very natural way of thinking, so it’s not hard to see why it’s popular. Going with tried-and-true (yet boring) examples, OOP embraces things like a Car class, where Car is an abstract class, and different ‘makes’ and ‘models’ can inherit from it. There is a lot of rigmarole around inheritance rules and proper structure, most of which are obsessed about because of the importance it plays in maintainability and extensibility.
// This is supposed to be Java, I don't know much.
public function CarFactoryFactoryFactory { // inside joke
float speed = 0;
// "getter" function
float getCurrentSpeed() {
return speed;
}
// "setter" function
void drive(new_speed) {
speed = new_speed;
}
}
protected function Honda extends Car {}
protected function Corvette extends Car {}
var corvette = new Corvette();
corvette.drive(100);
// Later extensibility? no problem!
public function Car {
private boolean is_fast = false;
}
Another factor that is often talked about, but not distinctly part of OOP is the concept of an interface. It usually refers to a description of a formal class implementation. These are the concrete details of how a function can be used, what it can do, what it returns, etc… it is kind of an engineering principle made real as a programming construct.
You will undoubtedly be exposed by a deluge of this paradigm in your programming career. I tend to think of it as wildly useful “in the large” and wildly absurd and constricting “in the small”. I’ll get to what that means later.
Doc, are you ready for the procedure?
Another paradigm that’s even more common than OOP is Procedural programming. This is where a vast majority of programs both past and present fall into. It is the simplest form, as it has hardly any structure. The gist is this: your code is read top to bottom, and each statement finishes before continuing to the next one. Let’s see an example:
function godModule() {
// wat.
some_global_state += 1; // is this a number?
// this does a lot of stuff....!
if(this && that || that + this) {
okayWhateverDoStuff();
} else {
ahNeverMind();
}
runThat();
runThisAfterThatWasCalled(); // please god, work!
loadSomeStuff();
makeAFancyPicture('images/my_face.jpg');
var my_cat_photos = downloadCatPhotos();
if(my_cat_photos.length > 100) {
notes.write('Dear diary, I really seem to like cat photos.');
}
loadImageSlideshow(my_cat_photos);
return bananas; // undefined error;
frobnicateAllTheThings(getFrobnicationKnobs()); // unreachable
}
In the spirit of making ridiculous and weird code examples, the above is a classic procedure. It has a lot of responsibility. It excretes code smells, and it is a writhing beast. Sadly, this is quite mild compared to real code I’ve seen, and I TRIED to make it suck. Often times, people “monkey-patch” or even “duck-punch” their code to work in ways it ought not too, simply because they didn’t understand how it interacted elsewhere. You can clearly see that a lot of stuff is going on here, much of which is erroneous and unrelated.
Straw-man arguments aside, this is not uncommon, and barely scratches the surface. However, procedural code is often times necessary, and can written reasonably and elegantly.
Often times, code is not really procedural – but the program you write is, for all intents and purposes. In the above example, the code is meant to execute line by line. Generally this works, but this is another gotcha that can spring on you, depending on how far down the rabbit hole you go (network requests, latency, promises, threads, semaphores, mutexes, processes, etc…)
Listen up, I’ve got to declare something.
If, on your journey, you weren’t content with being a programming wage-earner, and decided to dig further, you’ll probably have stumbled upon another paradigm – declarative.
I just want to say that declarative is one of my personal favorites – it’s so terse and elegant! It’s also so fresh, and so clean (clean), so its got that going for it.
Oddly enough, you might have to write some procedural code just to achieve it – but the API you produce will be declarative, which is the important part. The fact that this sort of dependency exists should be a clue that declarative programming is not a one-to-one comparison, but it has some cross-cutting similarities and is still a paradigm in its own right.
var max_width = 480;
var images = getImages().resizeThem(max_width).optimizeFilesize();
// accepts an array, or a single element
postToFacebook(images);
// ... or, more functionally:
// since it accepts both array and single element,
// we can call it for each function.
images.forEach(postToFacebook);
Declarative therefore is a way to write your tools in a way that allows the user of said tools to “declare” their intentions. Rather than say, getting some value, and then checking if it’s within the bounds of another value, then doing some behavior if so, you would just say “do this thing”. You’re in effect saying – “I don’t care how it’s done, just do it”. The program should figure the rest out. The figuring the rest out can often be procedural, hence my earlier statement. Whether or not this is case depends on the limitations of the language. Some languages have these concepts built right in, others are very generic.
Function, function, what’s your composition
With the exception of OOP, the functional paradigm builds heavily on the previous ones. However, there is some blur in what functional programmings means and what it is in computing today.
So you know about functions. Those little packets of usefulness have been helping you out all over the place. You’ve been diligently organizing them into neat helper that are clean, and well documented, and (hopefully unit tested) to make your code that much more robust. Each function is well defined, with inputs and outputs that are like a “black box” – it shouldn’t matter what you put in, the same result should always come out given a specific input. These black boxes are predictable, have known, reasonable inputs, and handle edge cases, like incorrect data types and typical errors such as Range, Index and Key. They are not concerned with other parts of your program, and are therefore highly decoupled – making change easy and negotiable in the future. They don’t do too much (spaghetti code) and don’t do too little (ravioli code). It’s that damned Goldilocks effect again – it seems to crop up everywhere in the universe, doesn’t it?
Functional programming makes functions the core of everything. In fact, in a purely functional language, functions are the only construct you use. While this may not seem any different from what you’ve been doing (“I’ve been writing functions already!”) functional style stresses the absolute adherence to all functions, all the time. But it’s not just writing functions – these functions need some rules. Functional programming tries to instill things like referential transparency – the notion that functions always evaluate to the same thing, regardless of context. Calling a function in one place shouldn’t change the way it works, when it’s called somewhere else. You’d be surprised how often this phenomenon is found (and abused) in other paradigms.
Another important tenet of functional programming is the lack of state. State, being naturally mutable (able to be changed), can be useful, but comes at a cost. Mutation of state over the course of program execution means behavior that depends on that state may become unpredictable. It’s just another way that things can go haywire in a program, making it harder to reason about and debug.
State is all kinds of useful – for example, a simple for loop uses an “iterator” variable, which stores the current iteration value, so you can loop while increase or decreasing (1, 2, 3, 4…). You might also keep track of some changing thing that involves user input – a mouse position, a keyword value. The fact this seemingly fundamental property is both undesirable and unnecessary in functional languages often perplexes people, who feel it is one of the identifying traits of a computer program.
// BAD KITTY!
// store our individual values as an array.
some_array = new Array(100);
function stuff() {
// Where da arguments? Oh wait...
for(i = 0; i < some_array.length; i++) {
// so far, so good...
doStuffWithAValue(some_array[i]);
// D'oh! Now we're hosed.
some_array[i] = random(10000000);
}
}
function things() {
// no arguments either? jeez...
some_array[random(1000)] = false;
}
// ...meanwhile, in another function...
function iHaveNoIdeaWhatsGoingOn() {
if(maybe_true || probably_no_true) {
things();
}
stuff();
}
Wow, look at all that global state.
So how do we solve this problem of not having state? Simple – you just keep calling functions, passing in “updated” state as arguments. Instead of having a state that is changed and re-referenced across multiple functions (breaking the de-coupling and separation-of-concerns rules), you simply pass the new function the updated state. You get the same effect, but you can breathe easy knowing that was completely unaltered when it came into the function.
Wait… what new function? Ahh, that’s another important thing to know and remember. Functions returns things! Yes, okay, that’s elementary. But wait – functions can return new functions! And those functions can have some arguments already applied! This understanding is crucial to functional programming.
With this use comes another tenet – partial application. You see, functions may have arguments – a seemingly unlimited number that you can define and pass – but it’s advised to keep the number of arguments used to a minimum. In functional style, that minimum is preferably one – and the number of arguments (arity) is actually used to defined different functions (overloading). When you have many arguments that need to be passed in, you have to “partially apply” them – apply them one function call at a time. This can mean creating a new function with one argument applied, which can then be called again with the remaining arguments, applied over and over, until all arguments have been “used up”.
You will also find yourself intimately involved in things like function composition, and if you use a pure functional language, type signatures – ways (like interfaces) to describe how a function should be used (that are actually enforced at runtime).
I’ll leave it there for now, but there is a lot more ground that can be covered – the abstract mathematical premise of lambda calculus, for which functional programming is based on notwithstanding.
One important understanding going forward is the concept of chaining functions – combining the output of one function into the input of another, ad infinitum. This “flowing” is the keystone for concepts provided ahead.
Go with the flow (maaaaaan)
Hopefully you’ve been totally invigorated by computing and programming, and if so, you’ve probably dug further. You might just hit a gem – a shiny, even mystical gem – the gem of data-flow programming, and the crux (finally!) of this article.
Data flow programming is somewhat ambiguous, and is generally categorized as a subset of declarative.
On a conceptual, intuitive level, functional programming and data-flow programming are very similar. The concept of chaining, connecting (like Lego!) functions to each other and using one output as another input is the mainstay of data flow programming. There are merely some formalisms that define data flow specifically – a graph (data structure) of function calls (or operations) that dictate the overall flow of a program. The odd, and slightly ironic thing, is that this concept is vital to all programs – even procedural! A procedure must usually be compiled to object code (or interpreted on the fly), and that object code will have some representation of the program call graph, in the form of an abstract syntax tree. So then… the more things change, the more they stay the same.
However, this is all “in the small”. This is not necessarily what data flow is concerned with, thought it can be used to describe such examples. It is possible to switch context and think of data flow programming not as implementation details, but rather, overall structure of a larger system and code base. You see, we’re scaling up these principles of computing to the architecture of our code! Truly amazing, the dizzying complexity that arises from simple rules (which reminds me, Cellular Automata is another paradigm of it’s own, which focuses on these odd phenomenon of rules and emergent behavior.)
Data-flow example - “piping”
If you’ve programmed even a little, you’ve probably come across piping, even if you didn’t know it. The term piping comes from UNIX, where operating system commands can be piped together, filtering and transforming data as many times as necessary. For example, consider a command to search for some files, based on the directory listing, filter the results by a keyword in the file contents, and then execute that as the input to another program we made up:
ls | ag 'cat-photos' | post-to-facebook --with-pics --given-input
Okay. This is a ridiculous, nonsense example. But, we did the three things above. Each operation in the example is separated by a |, and it demonstrates both in real code, AND visually, what is happening. Those UNIX guys were pretty clever, eh? Nothing beats the speed and terseness, even today.
Data-flow example - Wolfram Language
I love Wolfram Alpha, and a lot of the what the Wolfram team has done. If you aren’t familiar, Wolfram Alpha is billed as a “computational knowledge engine”, that takes inputs (user given) and transforms it into facts, visual representations, and interactive models. After the success of WA, They’ve now released the engine behind it for public consumption – the “Wolfram Language”. I encourage you to watch the introductory video at http://www.wolfram.com/language/.
In the video, Stephen Wolfram (creator, prodigy, etc…) stresses the importance of the Wolfram Languages' ability to transform data, and continually transform data that was previously computed. This is demonstrated very powerfully in the video, with inputs and outputs being used to make more complex and exciting computations.
This is one context, though it’s a very large one – yet it’s simply using the principles of data flow programming! As you can see, the very act of using this paradigm allows for the creation of some extremely powerful tools. If the future of technology is the flow of constantly changing data (from sensors, inputs and computation), and consumption and computation of data (it is!), then this paradigm is the future of programming. I say that with extreme confidence, but feel free to mock me.
Parallel and distributed dataflows – the “future” of computing.
I can also say with extreme confidence that the future of computing is something that is, or is very similar to, parallelism. With that assumption firmly in place, we need to ask ourselves; “what does parallel programming look like”? Fortunately, this problem has also been tackled and is already pretty well established. Though some applications in computing have floundered for a while, it is highly sought after topic, particularly as it applies to artificial intelligence. Interestingly enough, this trajectory of computation is how the brain works, insofar as we understand it. The brain is a highly distributed and parallel machine. As we increase computational power, so too, we increase the mirroring of computers to brains. It is an eerie coincidence that perhaps we might give pause to.
With the exception of your typical “map, reduce” class problems, I have literally no experience in this realm, so I’ll leave this topic as merely an aside for curious readers. I bring it up because it is another piece of the bigger puzzle, and well, it’s damn cool.
Hopefully this whirlwind of topics has been very interesting, and it has at least led you on a path towards understanding the evolving themes of programming. It is amazing to see the very real “paradigm shifts” that exist in programming, and how it simple ways of thinking can have profound effects on the structure and application of your program.
Optional side note: data flow and code-as-data
So, when we write our programs to be used in larger systems, we often want to think in terms of data flow. It can often be useful when we think of code as data, where the program we write to do something also describes the actual data it is performing the computation on. This is not the best explanation, but this is some groovy mind-bending shit, once you get the grasp of it (I hardly do.) If you’re curious to learn more about this, look into “code-as-data” and “algebraic data structures”. It’s definitely next-level programming, so it might be wise to preemptively take some introductory abstract algebra courses before jumping in head first. If you don’t get it at first – don’t fret! It’s a very advanced topic.
]]>All concepts
![]()
Final logos
![]()
Final logos + detail
![]()
![]()
Alternate concepts
![]()
Background elements
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()